今日中国,各行各业经常开展顾客满意度的调查研究。除了电信运营商、银行、家电制造商、汽车制造商等企业外,政府机关比如烟草专卖局、铁道部、税务局、城管、公安系统等也开始针对公众展开满意度调查。
这些组织对满意度调查结果很关注。除了对满意度得分有要求外,往往还希望能够提升满意度分值。很多组织都聘请了第三方调查机构进行满意度调查,对满意度分值、内部得分排序等结果比较认可,认为和实际情况相符。但是,在提升满意度方面,虽然第三方机构也提供了改进方案,但是委托方往往发现或者提升方案无法指导执行,或者即使有可实施性,实施结果却差强人意。为什么会出现这种结果呢?
答案是:满意度研究技术含量要求高。如果第三方调研机构在数据分析过程中没有采用合适的计算和分析技术,在提供改进方案方面往往是误导委托方的资源配置。在咨询界有一句行话,“garbage in ,garbage out ”(输入拉圾,输出的也是拉圾),这句话在市场研究行业同样适用。在数据采集过程中如果把关不严,或者设计的采样方法有问题,都会导致数据质量不佳。除此之外,即使输入的是良品数据,如果加工设备用错了,或者不按操作规程使用(用错了分析计算工具,或者不按照要求使用相关分析计算工具),输出的依然是拉圾。
在哈佛商业评论(HBR)中文版2009年第6期上,文章《如何测出客户心中最爱》讲述了采用一种“最大差异量表”(MaxDiff)的技术,其结果与我们日常采用的重要性1-10分评分方法结果完全不同。随着新技术的介入,所得结果越来越接近反映实际情况。这篇文章,描述的是市场研究技术采用不当会误导客户的极佳案例。
满意度研究领域,目前大多数市场研究公司都声称采用结构方程模型展开研究。结构方程模型( Structural Equation Model, SEM)集合多种传统统计分析方法的优点,已成为适用广泛的分析方法,在心理学、社会学、教育学及管理学等领域内均有应用。近年来在管理学领域内国际学术杂志上发表的实证研究文章中,应用结构方程模型分析数据的约占发表总数的40%。但是,很遗憾的是,笔者发现很多研究公司在使用结构方程模型方面很不严谨,而客户公司往往没有相关专家,所以无法发现其问题。这方面的问题,即使在高校管理学应用研究方面也经常出现。2007年3月《数理统计与管理》杂志上有一篇文章《结构方程模型应用陷阱分析》(作者:刘军、富萍萍)分析得比较到位,笔者在此不在赘述,有兴趣者可以参见此文。
1、结构方程模型中的缺省处理问题:
在数据采集过程中,总会有一些问题部分受访者无法回答,这样某些问题纪录就会产生缺省。如果运行结构方程模型,这些含缺省值的变量如何处理?正确的方法时,如果缺省值在10%以下,可以采用均值替代或者用其它相关变量来估算缺省值的方法来补充数据,然后运行模型。但是如果缺省率过高,就不能采用上述的方法。如果还是强制运行模型,不仅仅是缺省率比较高的变量关系出现错误,整个模型所有变量之间的关系都会受到影响,产生错误结果。遗憾的是,笔者多次看到过调查中某些变量高达20-50%的缺省率,依然采用均值替代然后运行结构方程模型的做法。
笔者主持的一项耐用产品售后服务满意度调查中,收费用户比例大概在27%左右,投诉比例接近10%,一次修复率大概在70%左右。那么如何处理这些数据呢?收费用户27%,表示只有27%的受访者可以对收费环节相关问题进行答复;投诉比例10%,也就是说对投诉处理相关问题的回答缺省率90;,一次修复率70%,表示有30%受访者对未能一次修复的相关问题无法回答。很明显,上述3个隐变量(收费评价、投诉评价、非一次修复评价)不能直接进入结构方程模型计算分析,而需要单独处理。但是这些要素之间在改进排序方面如何比较呢?笔者采用的方法是:
收费用户发生率27%,收费VS不收费用户的满意度评价落差2分;发生率*落差=0.54。收费评价的显变量包括收费合理性、费用公开透明、费用发票开具等内容。
一次维修不成功发生率30%,一次维修不成功用户与一次维修成功用户满意度评价得分相差14分;发生率*落差=1.2。非一次维修成功评价包括原因解释合理、问题最终
解决时间、解决方法等内容。
投诉发生率10%,投诉过用户与未投诉用户满意度评价得分相差21分;发生率*落差=2.1。投诉评价包括投诉受理、处理及时、处理结果等内容。
因此,上述3个要素应该重点关注投诉,设法降低投诉率或者提高投诉处理得用户的评价分值。
2、结构方程模型中的计算方法问题:
对于我们常用的LISREL、AMOS等软件包来讲,每个潜变量都应当是反映型的。从变量特性来讲,“反映型”(reflective)是指潜变量决定观测变量(可度量变量) ,即我们测量的是潜在概念的外在反映;而“构成型”(conformative)指的是由可度量变量以某种方式共同组成潜变量,构成型潜变量由可见变量共同决定。
我们通常用X、Y表示外生变量和内生变量的观测变量(显变量),用KSI(ξ)表示外生变量(隐变量),ETA(η)表示内生变量(隐变量)。
反映型关系可以表示如下:
X=X在ξ上的载荷值×ξ+误差
Y=Y在η上的载荷值×η+误差
构成型关系则可以表示如下:
ξ=∑(ξ在Xi上的载荷值×Xi)+误差
η=∑(η在Yi上的载荷值×Yi)+误差
在中国用户满意指数(CCSI)研究中,由于要针对不同行业、不同部类进行对比,并且调查数量巨大,所以在CCSI模型中采用了比较少的变量,而这些变量之间的相关性比较强(耐用消费品模型只有18个问题),因此采用反映型关系反映变量之间的联系是没有问题的。
但是在企业委托研究中,除了了解用户满意度分值外,还需要运用调查结果指导改进用户满意度。这样的话,调查问卷中设计的问题比较细致,问题量也比较多,很多问题之间的相关关系不强,实际上结构方程模型中显变量和潜变量之间的关系很多都是构成型的,整体模型则可能是混合型的。这样用LISREL和AMOS等软件包来运行是不合适的。而PLS软件包则是可以计算构成型关系的软件包。
除了上述原因为外,LISREL等软件包还要求数据是正态分布的,而满意度研究的数据则是右偏分布的,而PLS软件包对数据的分布没有要求,进一步表明PLS软件包是计算满意度研究结构方程模型的正确选择。
下面笔者用某银行营业厅满意度的研究数据来说明采用不同计算方法导致的结果差异(样本量:998)。
下图是LISREL运行银行营业厅满意度的结果图。该模型的RMSEA=0.061, NFI=0.93, NNFI=0.94, GFI=0.91。从LISREL的拟合指标看非常好。本模型在前期做过试调查,进行过验证性因子分析和可靠性分析(很多市场研究公司都跳过这一步,实际上这一步非常重要,是必不可缺的)。
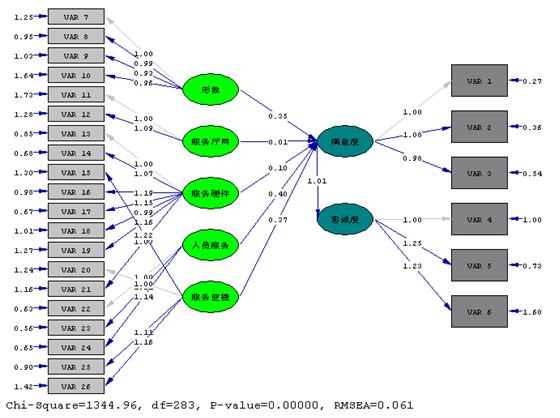
上述模型中,隐变量之间的影响系数可以通过LISREL得到。但是显变量X和隐变量KSI之间的影响系数却无法得出。笔者了解的很多研究公司,采用了将X和KSI之间的标准化载荷系数归一后,作为某因变量KSI和X之间的影响系数。这种方法在理论上存在重大缺陷,但是绝大部分的委托方是不了解的。
下面比较一下用PLS算法和上述LISREL算法得到的结果差异,以及基于上述不同结果,提供给委托方的改进建议排序的不同(为了简化,只考虑了2个隐变量对应的显变量)。
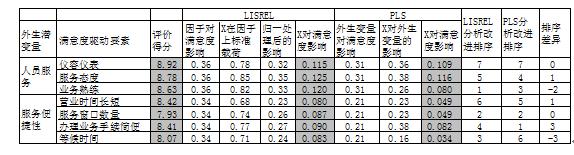
无论采用PLS算法还是LISREL算法,显变量(观测变量)的得分是一样的,但是隐变量(结构变量)的得分确不一样。不过,在决定观测变量的改进建议时,不需要隐变量的得分。我们提取上述模型的2个隐变量对应显变量进行对比分析。数据显示,采用迪纳市场研究院开发的PLS软件和LISREL软件计算分析得到的结果差异很大。基于显变量的得分,以及他们对满意度的影响大小,可以计算得到提升满意度分值的显变量改进排序。从上表的最后三列可以看出,不同方法推导出的改进建议排序结果差异很大。
综合前面提及的LISREL用于满意度研究数据计算的两大局限性,我们建议市场研究公司尽量采用PLS软件来研究满意度。只有这样,才能给委托方提供有效的改进提升建议。
| 